| Kapitel 4.4 Datenmodellierung für das AIS | |
(Auszug aus der Diplomarbeit von Ralph Leipert: "Analytische Informationssysteme als Basis des Risikomanagement der Unternehmung") 4.4.1 EinleitungDie Datenanalyse hat beim Aufbau eines AIS eine wichtige Funktion. Zur Datenanalyse gehört nicht nur, daß die relevanten Daten für das Risikomanagement spezifiziert und in den DBS lokalisiert werden, sondern auch, daß ein leistungsfähiges Datenmodell entwickelt wird. Dieses Datenmodell muß nicht nur den Anforderungen von operativen DBS genügen, sondern auch noch den Anforderungen der Erweiterbarkeit, Schnelligkeit und Flexibilität von Datenanalysen. Daraus folgt, daß schon in der Analysephase beachtet wird, daß die Daten auch in aggregierter Form gespeichert werden. Diesen Anforderungen genügen die herkömmlichen Datenmodelle aus den operativen Systemen nicht. Durch die Speicherung der Daten in aggregierter Form kann das Performance-Problem zum Teil gelöst werden. Neben relationalen DBS kommen auch objektorientierte und multidimensionale DBS bei Data Warehouse-Lösungen zum Einsatz. Die Datenmodellierung erfolgt in mehreren Schritten. Zur Abbildung eines bestimmten Systems in einer Datenbank muß zuerst der Umfang der Realwelt eingegrenzt werden. Im zweiten Schritt muß diese eingegrenzte Realwelt auf eine Datenbank abgebildet werden. Diese Abbildung entspricht nach ANSI/SPARC dem konzeptionellen Schema. Das konzeptionelle Schema muß dann in ein internes Schema umgesetzt werden. Die Abbildung des Realweltausschnitts auf ein konzeptionelles Schema erfolgt in zwei Schritten. Zuerst wird der Realweltausschnitt auf ein semantisches Datenmodell und dann auf ein logisches Datenmodell abgebildet.
Abbildung 4-13 Datenmodellierungsschritte 4.4.2 Semantische DatenmodellierungBei der Datenmodellierung von AIS sollte im Rahmen der Systementwicklung, wie bei den operativen DBS, vor der logischen Datenmodellierung die semantische Datenmodellierung erfolgen.102 Durch das semantische Datenmodell wird die semantische Lücke zwischen Realwelt und logischem Datenmodell verkleinert. Zur Abbildung der Realwelt in einem semantischen Datenmodell bedient man sich zumeist dem ERM. Dieses Modell genügt zwar meistens den Ansprüchen von operativen DBS, jedoch hat dieses Modell Probleme, Daten multidimensional abzubilden. Aus diesem Grund wird nach neuen Modellierungstechniken bzw. Datenmodellen gesucht. In der letzten Zeit hat man sich mehr mit der technischen Umsetzung von AIS beschäftigt als mit der Datenmodellierung. Dadurch kam es auch zur Vernachlässigung der Entwicklung geeigneter Werkzeuge zur Datenmodellierung, vor allem für semantische Datenmodelle. Aus diesem Grund existiert im Gegensatz zur logischen Datenmodellierung, wie z.B. das Star-Schema, bei der semantischen Datenmodellierung noch kein Konzept, welches die Anforderungen an multidimensinale Datendarstellung erfüllt. Bei der Datenmodellierung von AIS ist nicht die Realwelt die direkte Grundlage der Modellierung, da in den AIS nur Kennzahlen wie Absatzmenge, Umsatz, Gewinn, Cash Flow, ROI, RAROC, Zinssätze, Marktrendite usw. gespeichert werden. Die Datengrundlage für diese Kennzahlen liefern die operativen DBS bzw. externe Datenquellen. In den Unternehmen sind die semantischen Datenmodelle nicht immer vollständig, so daß auf diese nicht unbegrenzt zugegriffen werden kann. Dies bedeutet natürlich auch die Chance, vollständige semantische Datenmodelle für die transaktionsorientierten Informationssysteme und die AIS zu erstellen, welche auch in Zukunft gepflegt werden müssen. Das semantische Datenmodell muß auch die Anforderungen der Erweiterbarkeit und der Wiederverwendbarkeit erfüllen. Bei der semantischen Datenmodellierung der AIS müssen neue Wege gegangen werden, da die bisher verwendeten Datenmodelle die Multidimensionalität und die Aggregationen nicht unterstützen. Zuerst soll noch einmal das bislang in der Praxis für relationale DBS verwendete EERM vorgestellt werden. Im nächsten Kapitel wird ein Modellierungsvorschlag beschrieben, wie die semantische Datenmodellentwicklung aussehen könnte. Weitere alternative Modelle und Ansätze stellen Gabriel und Gluchowski103 (z.B. Application Design for Analytical Processing Technologies - ADAPT104) und Schelp105 vor. 4.4.2.1 Erweitertes Entity Relationship Modell (EERM)Da bei der Modellierung operativer relationaler Datenmodelle das ERM nicht allen Anforderungen entsprach, wurde das ERM zur besseren Darstellung der Entities und ihrer Beziehungen um einige Funktionen erweitert. Dies führte zur Entwicklung des erweiterten ERM (EERM). So kann man bei dem EERM Vererbungensmechanismen, Klassen- und Subklassenbildung, die aus der Objektorientierung bekannt sind, einbeziehen.
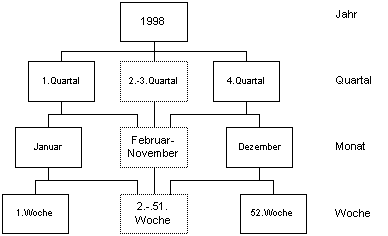
Abbildung 4-14 EERM Im oben stehenden EERM werden Vererbungsmechanismen dargestellt, die es im ERM nicht gibt. Der Entity-Typ Fahrzeug kann in zwei Subklassen (PKW, LKW) unterteilt werden. Dabei werden alle Attribute von Fahrzeug an die Subklassen weitervererbt. Die Subklassen haben wiederum eigene spezifische Attribute. Gehören die Entitys jeweils nur einer Subklasse an, wie im Falle der Fahrzeuge, so nennt man sie disjunkt (disjoin). Können die Entities mehreren Subklassen zugeordnet werden, so nennt man sie überlappend (overlapping). Der Entity-Typ Kunde kann auch in die zwei disjunkten Subklassen Privatkunde und Geschäftskunde unterteilt werden. Die Komplexitätsgrade (1:N, (min,max) oder (1, c, m)) wurden aus Übersichtsgründen weggelassen. Durch die Vererbungsmechanismen besitzt das EERM im Gegensatz zum ERM objektorientierte Ansätze, welche Chamoni neben Kapselung und Nachrichtenaustausch als Anforderung für zukünftige objektorientierte OLAP-Server sieht.106 Eine Erweiterung um eine multidimensionale Unterstützung der Modellierung könnte ein Weg zur Verbesserung der semantischen Datenmodellierung sein. Beispielsweise haben sich schon einige Autoren mit der Erweiterung des ERM um die Dimension Zeit auseinandergesetzt (z.B. TERM107, TEER108, ERT109). 4.4.2.2 Hierarchisches Dimensionen-ModellDie semantische Datenmodellierung von AIS muß multidimensionale Strukturen sowie Aggregationen unterstützen. Dies bedeutet im einzelnen, daß alle im Modell einzubeziehenden Dimensionen mit allen Hierarchiestufen modelliert werden müssen. Beispiel der Dimensionen: Der Cash Flow-Wert eines Produktes in einem Bundesland welches an einen Kunden im Zeitraum eines Monats verkauft wurde, hat die Dimensionen: Produkt, Region, Kunde und Zeit. Der Wert des Cash Flow bildet zusätzlich eine Dimension. Im Absatz- und Marketingbereich können viel mehr Dimensionen entstehen. Wenn man z.B. versucht, den Zusammenhang zwischen verkauften Autos und Region, Zeitintervall, Verkäufer, Kundengruppe, Fabrikat, Modell, Motorisierung, Farbe, Sitzform, Armaturenbrettausstattung, usw. festzustellen, so ist die Zahl der Dimensionen, die im Datenmodell dargestellt werden müssen zweistellig. Die Hamburg-Mannheimer Versicherungs-AG110 hatte beispielsweise in ihrem Schadenablauf-Controlling-System 11 Dimensionen zu modellieren, die mit der klassischen OLAP-Würfel-Datenmodellierung nicht in annehmbaren Antwortzeiten zu analysieren waren. Dieses Beispiel zeigt die Wichtigkeit der Modellierung der Daten mit den Dimensionen. Da Dimensionen von unterschiedlicher Ausprägung sein können, kann man die Dimensionen in folgende drei Kategorien einteilen: Dimensionsschema, Produkthierarchie und Kennzahlenschema. Im folgenden sollen diese Darstellungsformen kurz vorgestellt werden und abschließend in einem Dimensions-Kennzahlen-Zusammenhangs-Schema zusammengebracht werden. 4.4.2.2.1 DimensionenschemaEine mögliche Darstellungsform der Dimension ist das Dimensionsschema. Dabei werden die atomaren Daten aus den operativen DBS systematisch in höhere Stufen aggregiert. Bei der Dimension Zeit können die Tagesdaten zu Wochendaten aggegiert werden. Daraus werden dann Monatsdaten, Quartalsdaten, Jahresdaten und Gesamtdaten (z.B. seit Unternehmensgründung) berechnet. Zusätzlich können auch gleitende Werte modelliert werden, z.B. für die letzten 3 Monate. Zur Vereinfachung wird hier die Dimmension Zeit in vier Aggregationsstufen dargestellt. Die Aggregationsstufen sind in einer Hierarchie aufgebaut.
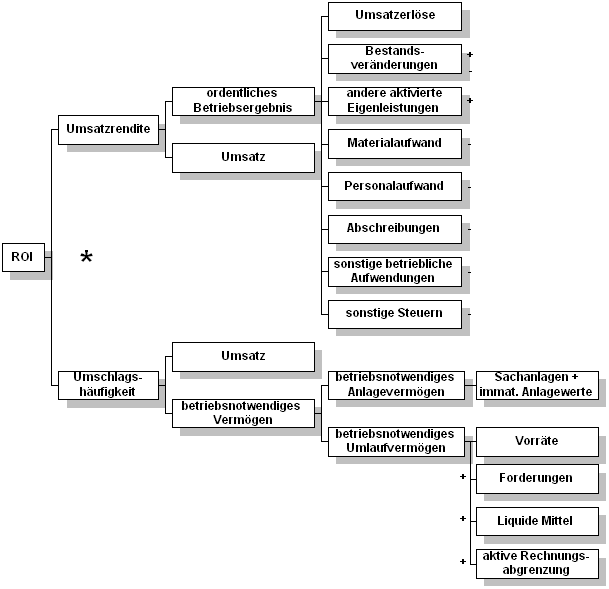
Abbildung 4-15 Dimensionsschema: Zeit Parallel zum Zeit-Dimensionsschama müssen noch alle anderen Dimensionsschemata modelliert werden. Hierbei sollten die Dimensionen entsprechend der Anwendersicht (use case) erstellt werden und nicht entsprechend der Realisierbarkeit in den DBS. Das Region-Dimensionsschema kann beispielsweise folgende sechs Aggregationen besitzen: Welt, Kontinent, Staat, Bundesland, Unternehmen, Werk. Je nach Unternehmensorganisation kann dieses Schema kleiner oder größer bzw. detailierter gestaltet werden. Es ist auch möglich, ein zusätzliches Dimensionsschema für die Unternehmensorganisation zu entwerfen. Dann würden die letzten beiden Aggregationsstufen im Dimensionsschema Region wegfallen und das Dimensionsschema Unternehmensorganisation z.B. die Aggregationsstufen Konzern, Mutterunternehmen, Tochterunternehmen und Werk enthalten. Dimensionsschemen können aber auch parallele Aggregationsstufen besitzen. Ein Beispiel hierzu wird im Kapitel „Produkthierarchie beschrieben. 4.4.2.2.2 KennzahlenschemaMittels hierarchischer Bäume können Kennzahlen dargestellt werden. Im Gegensatz zu den Dimensionsschemen werden in diesen hierarchischen Bäumen nicht Daten in verschieden Aggregationsstufen dargestellt, sondern in Konsolidierungsstufen. Im folgenden soll kurz am Beispiel des RORAC der Aufbau eines Risikokennzahlenmodells dargestellt werden. Der Aufbau eines Kennzahlenmodells ist der erste Schritt zu einem Risikokennzahlenmodell. Im zweiten Schritt wird das Modell um den Risiko-Faktor erweitert. Wie im Kapitel „Risikomanagement“ beschrieben, werden die Risk Adjusted Profitability Measurements (RAPM)-Kennzahlen vom Return On Investment (ROI) abgeleitet. Die Herleitung dieser Kennzahl nach Gesamtkostenverfahren sehen wir im folgenden Kennzahlenschema.
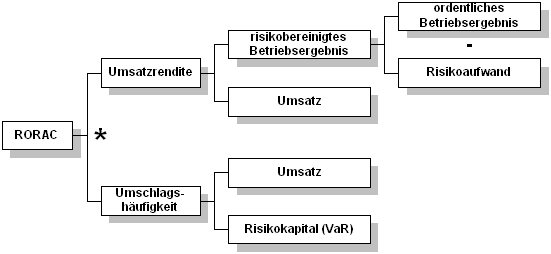
Abbildung 4-16 Kennzahlenschema: Return On Investment111 Eine solche Betrachtungsweise ermöglicht eine detaillierte Ursachenanalyse einer geänderten Rendite oder einer Abweichung der Rendite von einer Zielrentabilität.112 Für die semantische Datenmodellierung ist eine solche Sichtweise auch deshalb interessant, weil das Aufsplitten der Kennzahl bis in das kleinste Detail zeigt, welche Daten für die Berechnung notwendig sind. Dabei kann davon ausgegangen werden, daß wenn die Kennzahlen bis in die atomaren Bestandteile modelliert sind, diese atomaren Bestandteile in den operativen IS existieren. In diesem Kennzahlenschema sind die Bestandteile des ordentlichen Ergebnisses, der Umsatz, die Position „Sachanlagen+immaterielle Anlagewerte“ und die Bestandteile des betriebsnotwendigen Umlaufvermögens in den operativen IS, z.B. in der Datenbank des Rechnungswesens, enthalten. Wird das ROI-Kennzahlenschema durch Einbezug des Risikos auf den RORAC erweitert, so erhält man folgendes vereinfachtes Schema.
Abbildung 4-17 Kennzahlenschema: RORAC In diesem RORAC-Kennzahlenschema wird das ordentliche Betriebsergebnis wie im ROI-Kennzahlenschema berechnet. Dieses wird dann noch um einen Risikoaufwand gekürzt. Das Risikokapital kann mittels der VaR-Methode berechnet werden. 4.4.2.2.3 ProdukthierarchieschemaEin Produkthierarchieschema ist ähnlich dem Kennzahlenschema aufgebaut. Hierbei wird dargestellt, aus welchen Teilen ein Produkt hergestellt wird. Der Vorteil beim Aufstellen eines solchen Schemas liegt in der Darstellung von Beziehungen der Einzelteile mit den Dimensionen und Kennzahlen. Dadurch wird die Möglichkeit geschaffen, durch die Drill-down- Funktion die Ursachen für die Höhe - bzw. die Veränderung der Höhe - einer Kennzahl eines Produktes zu bestimmen. In einer Produkthierarchie können aber auch Aggregationen dargestellt werden. Beispielsweise kann das Produkt Fahrrad durch die Aggregationsstufen Gesamt, Großteile, Kleinteile und Kleinstteile dargestellt werden. In der folgenden Abbildung werden Aggregationen und Konsolidierung in einem abgebildet. Dabei kann es auch zu parallelen Hierarchiestufen kommen. Diese parallelen Hierarchiestufen können aber auch in einem einfachen Dimensionsschema modelliert werden. Die parallele Hierarchiestufe wird durch eine gestrichelte Linie gekennzeichnet.
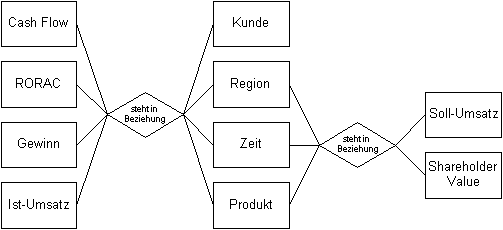
Abbildung 4-18 Produkthierarchieschema: Fahrrad 4.4.2.2.4 Dimensionen-Kennzahlen-Zusammenhang-SchemaZu den vorgestellten Darstellungsformen sollte eine Datensicht entworfen werden, welche die Zusammenhänge zwischen Kennzahlen und Dimensionen darstellt, das sogenannte Dimensionen-Kennzahlen-Zusammenhang-Schema (DKZS). Verbindet man die Dimensionsschemen in einem DKZS, so entsteht ein multidimensionaler Datenwürfel. Diesen Datenwürfel grafisch darzustellen bringt einige Schwierigkeiten mit sich, vor allem der Übersichtlichkeit und der Transparenz der Zusammenhänge wegen. Dieses DKZS kann durch ein ERM dargestellt werden.
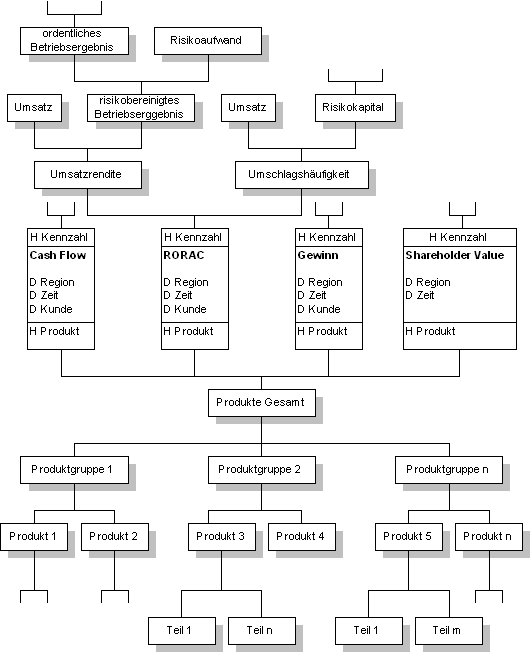
Abbildung 4-19 Dimensionen-Kennzahlen-Zusammenhang-Schema Haben mehrere Kennzahlen die gleichen Dimensionen, so können diese auch in demselben mehrdimensionalen Datenwürfel dargestellt werden. Werden für Kennzahlen andere Dimensionen benötigt, so muß für diese Kennzahlen ein neuer Datenwürfel modelliert werden. Überschneiden sich die Dimensionen mehrerer Datenwürfel, so können diese Datenwürfel wieder über die gemeinsamen Dimensionen in Beziehung (OLAP-Join) gesetzt werden.113 Dadurch entsteht ein großes mehrdimensionales Geflecht. Die Darstellung eines solchen EERM bis in alle Details - mit allen Dimensionsschemata, Kennzahlenschemata und Produkthierarchien - würde die Darstellungsform sehr schnell unübersichtlich werden lassen. Deshalb setzen die meisten Unternehmen ab diesem Zeitpunkt mit der logischen Datenmodellierung fort. Damit aber die semantische Datenmodellierung vollständig ist, sollte eine Lösung der semantischen Datenmodellierung gefunden werden. Im folgenden wird ein vereinfachtes semantisches Datenmodell vorgeschlagen, welches der vollständigen semantischen Datenmodellierung näher kommt. Für das folgende Datenmodell wird zur Vereinfachung ein RMS mit nur folgenden Kennzahlen angenommen: Gewinn, RORAC, Cash Flow und Shareholder Value. Im Mittelpunkt der Modellierung soll das Produkthierarchieschema und das Kennzahlenschema stehen, da diese zwei Dimensionen besonderer Bedeutung im Unternehmen bzw. RMS zukommt. Der Vorteil bei dieser Methode ist, daß die Kennzahlen bis in die atomaren Daten aufgespalten werden und auch die Produkte bis in das kleinste Einzelteile dargestellt werden. Diese atomaren Daten können dann in den operativen IS identifiziert werden. Die übrigen Dimensionen werden in diesem Modell gesondert modelliert und mit den Kennzahlen durch Auflistung in Beziehung gestellt. Diese Aufteilung ist auch deshalb sinnvoll, weil in den operativen IS kein Zeitbezug, Regionenbezug und Kundenbezug modelliert ist, sondern erst durch die Verbindung der DBS entstehen. Die Konsolidierung und Aggregation der Daten erfolgt erst nach dem Filtern der atomaren Daten aus den operativen IS. Die Beziehungen zu diesen Dimensionen werden aber trotzdem in den Kennzahlen mit eingebracht. Dadurch gehen auch der Informationsgehalt und die Mehrdimensionalität nicht verloren.
Abbildung 4-20 Vorschlag für ein Semantisches Unternehmensdatenmodell Dieses Datenmodell kann in ein logisches relationales oder ein multidimensionales Datenmodell überführt werden. Beispielsweise werden in einem Star-Schema die Dimensionsschemen in Dimensionstabellen und das DKZS in einer Faktentabelle abgebildet. 102 Vgl.: Schelp, J. (1998), S.264 103 Vgl.: Gabriel, R. / Gluchowski, P.: (1997), S.18-37 104 Vgl.: Bulos, Dan (1998b), S.251-261 105 Vgl.: Schelp, J. (1998) S.263-276 106 Vgl.: Chamoni, P. (1998b), S.247 107 Vgl.: Klopprogge, M.R. (1983), S.473-508 108 Vgl.: Elmasri, R./ Al-Assal, I. / Kouramajian, V.; (1990), S. 249-264 109 Vgl.: Knolmayer, G. / Myrach, T. (1996), S. 68; Loucopoulos, P. et al., (1991), S. 129-152; Theodoulidis, C. / Loucopoloulos, P. / Wangler, B.: (1991), S. 181-204; Theodoulidis, C. / Loucopoloulos, P. / Wangler, B. (1992), S. 87-115; 110 Vgl.: Lühmann, P. / Erben, E. (1998), S. 33 111 Vgl.: Coenenberg, Adolf G. (1993), S. 611 112 Vgl.: Coenenberg, Adolf G. (1993), S. 612 113 Vgl.: Gabriel, R. / Gluchowski, P. (1997), S.26
|
|