| Kapitel 4.2.3 Anforderungen an die Datenmodellierung in AIS | |
(Auszug aus der Diplomarbeit von Ralph Leipert: "Analytische Informationssysteme als Basis des Risikomanagement der Unternehmung") An die Datenmodellierung in AIS werden einige Anforderungen gestellt. Diese Anforderungen wurden in der Definition des Data Warehouse genannt und werden in diesem Kapitel beschrieben. Durch diese Anforderungen kann gewährleistet werden, daß sich die Daten für Analysezwecke eignen.
4.2.4 Klassifikation von Data WarehouseDie technische Realisierung eines Data Warehouse kann sehr unterschiedlich aussehen. Aus diesem Grund sollen in diesem Kapitel verschiedene Varianten des Data Warehouse klassifiziert werden. Diese verschiedenen Varianten entstanden durch unterschiedliche Vorgehensweisen beim Aufbau eines Data Warehouse. NCR66 unterscheidet dabei folgende Kategorien: Data Basement, Data Junkyard und Data Warehouse.
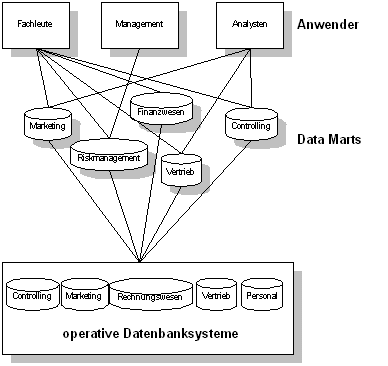
Data Basements Data Basement wird von dem Begriff „Kellergeschoß“, in dem viele einzelne Keller existieren, abgeleitet. In einem Keller werden Sachen abgelegt, von denen man denkt, daß sie noch irgendwann einmal gebraucht werden. Dabei hat jeder, der einen Keller hat, seine eigene Sicht auf diese Dinge. Genau so verhält es sich auch mit einem Data Basement. Ein Data Basement besteht aus vielen kleinen Data Marts, auf die jeweils eine spezifische Anwendergruppe (z.B. Marketing, Vertrieb, Risk Management, Führungskräfte) zugreift. Diese Data Marts werden jeweils von der spezifischen Anwendergruppe geplant, erstellt und benutzt. Diese einzelnen Anwendergruppen haben ihre spezielle Sichtweise auf ihre gespeicherten Daten. Der Vorteil dieser Lösung besteht darin, daß der Integrationsaufwand für den Aufbau eines ZDW entfällt, was jedoch längerfristig zu einem Nachteil führen kann. Es können durch diese Vorgehensweise viele Probleme entstehen. Das Data Basement braucht viel Speicher, vor allem deswegen, weil viele Daten mehrfach gespeichert werden. Außerdem müssen alle Data Marts regelmäßig bzw. dauerhaft gepflegt und erweitert werden, was viel Ressourcen an Mitarbeitern und Geld verschlingt. Aus diesem Grund ist das Data Basement keine effektive Lösung zur Unterstützung von MSS.67
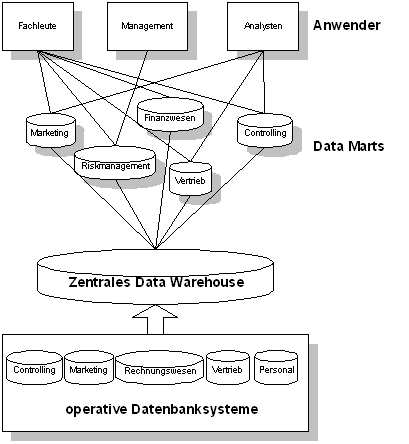
Abbildung 4-5 Data Basement Data Junkyard Junkyard heißt übersetzt Schrottplatz. Ein Schrottplatz ist wie ein großes Lagerhaus organisiert. Dort werden regelmäßig alte Maschinen, Haushaltsgeräte, Einrichtungen und Autos gelagert. In ihrer Gesamtheit sind die Gegenstände nicht verwertbar, wenn man die Gegenstände jedoch in ihre Einzelteile auseinanderbaut, haben diese z.B. als Ersatzteile noch einen Nutzen. Diese Teile werden in einem Lagerhaus, sortiert nach ihrem Nutzen, aufbewahrt. Ein Data Junkyard setzt sich auch aus einem ZDW und, darauf aufbauend, vielen kleinen Data Marts zusammen. Diese Data Marts werden mit Daten aus dem ZDW gespeist. Das ZDW wiederum, wird mit Daten aus den operativen Systemen bzw. mit Daten aus externen Quellen gefüllt. Der Vorteil zu den Data Basement liegt darin, daß die Daten alle zentral verwaltet werden, so daß alle Daten in den Data Marts die gleiche Datengrundlage haben. Somit erfüllt das Data Junkyard Integritäts- und Konsistenzbedingungen. Ein weiterer Vorteil liegt in der einfachen Skalierbarkeit durch hinzuzufügen neuer Data Marts.
Abbildung 4-6 Data Junkyard Bei diesem Konzept gibt es wieder zwei verschiedene Entwicklungsrichtungen. Während die eine Entwicklung in die Richtung geht, daß im ZDW nur Daten der höchsten Granularität gespeichert werden und keine aggregierten und konsolidierten Daten, geht die andere Entwicklung in die Richtung, daß im ZDW auch aggregierte und konsolidierte Daten gespeichert werden. Die erste Entwicklung hat den Vorteil, daß nicht so viele Daten repliziert werden müssen und dadurch Speicherplatz gespart wird. Der Nachteil liegt, wie beim Data Basement darin, daß der Anwender wissen muß, in welchem Data Mart welche Daten gespeichert sind. Die zweite Entwicklung hat den Vorteil, daß die gesamte Datenbasis konsistent ist, so daß Abfragen auf die einzelnen Data Marts die gleichen Ergebnisse liefern müssen, wie Abfragen auf das ZDW. Diese Architektur wurde auch im Kapitel „Architektur und Komponenten des Data Warehouse“ ausführlich beschrieben und stellt das am weitesten verbreitete Konzept dar. Data Warehouse Das Data Warehouse, wie es NCR in der Veröffentlichung68 bezeichnet, hat im Unterschied zu den zwei vorhergehenden Varianten nur eine Datenbasis. Auf diese Datenbasis greifen alle Anwender zu. Dies hat den Vorteil, daß alle aggregierten Daten zentral verwaltet werden und dadurch die Datenkonsistenz gegeben ist. Der Nachteil liegt in der Performance, da keine dezentralen Data Marts in den jeweiligen Fachabteilungen existieren und somit die Schnelligkeit der Abfrageergebnisse von der Netzleistung abhängig ist. Außerdem existiert ein weiterer Performance-Verlust dadurch, daß alle Benutzer im Data Warehouse verwaltet werden müssen sowie der Datensuchprozeß durch die große Datenmenge länger dauert. Den Sicherheitsaspekt sollte man dabei auch nicht vernachlässigen, da es in einem Data Mart leichter ist, die Benutzer zu verwalten und die kritischen Daten zu identifizieren und abzusichern, als in einem ZDW.
Abbildung 4-7 Data Warehouse 4.2.5 ZusammenfassungIm letzten Kapitel wurde das Konzept Data Warehouse vorgestellt. Das Data Warehouse ist die Datengrundlage für die OLAP-Werkzeuge. Aber auch andere Anwendungen können auf diese Datenbasis zugreifen. Die Daten im Data Warehouse besitzen andere Eigenschaften als die operativen DBS. Zu diesen Eigenschaften zählen vor allem der Zeitbezug, die Themenorientierung, die Konsistenz und die Multidimensionalität. Im Gegensatz zu den OLTP ist es durch diese Eigenschaften möglich, Analysen mit diesen Daten durchzuführen. Die Kombination der OLAP-Tools mit dem Konzept des Data Warehouse schafft im Bereich des Risikomanagements neue Möglichkeiten der Anwendungsentwicklung. Es können Anwendungen konzipiert werden, die das Risiko nicht nur identifizieren sondern darüber hinaus auch verarbeiten können und das mit einer annehmbaren Geschwindigkeit. Hierzu zählen z.B. auch die Ursachenforschung für die Risiken, die durch die Drill-down Funktion der OLAP-Werkzeuge ermöglicht wird. Voraussetzung für diese Funktionalität ist jedoch die Speicherung der Daten in verschiedenen Konsolidierungs- und Aggregationsstufen. Eine weitere Voraussetzung ist auch die Unterstützung von multidimensionalen Strukturen der Daten. Dadurch wird erreicht, daß die Ursachenforschung für Risiken bzw. Risikoveränderungen in Abhängigkeit von verschiedenen Dimensionen (z.B. Zeit, Region, Kunde, Produkt, usw.) betrachtet werden kann. Durch die Eigenschaft der Themenorientierung bekommt die Datenbasis einen vollständigen Datenbestand, der durch Konsistenz gekennzeichnet ist. Damit ist gemeint, daß alle für das Risikomanagement benötigten Daten in einem Data Mart gespeichert sind. In einem OLTP müßte sich das Risikomanagement die Daten aus verschiedenen operativen DBS (z.B. Rechnungswesen, Produktion, Absatz) zusammensuchen bevor eine Analyse auf die Daten möglich ist. Im Data Warehouse werden diese Daten auch benötigt, dabei werden die Daten jedoch regelmäßig mittels den Transformationstools von den operativen DBS in das Data Warehouse übermittelt und themenorientiert in einen konsistenten Zustand transformiert. Dadurch bleibt dem Anwender erspart, die Daten, beispielsweise mittels SQL-Befehlen, selbst zusammen zu suchen. Bisher wurde die Datenanalyse von der Anwenderseite beschrieben, d.h. der Anwender kennt die Zusammenhänge und läßt diese mit dem Computer berechnen und analysieren. Wird die Analyse jedoch von der Seite der Daten betrachtet, stecken noch viele verborgene Zusammenhänge in den Daten, die der Anwender nur erahnen kann. Für die Analyse der Datenbasis, um verborgene Zusammenhänge zu finden, bedient man sich meistens statistischen Methoden und Methoden der Künstlichen Intelligenz. Diese Datenanalysemethoden werden unter dem Begriff Data Mining zusammengefaßt. 64 Vgl.: Gluchowski, P. (1998), S.4 65 Vgl.: Gluchowski, P. (1998), S.4 66 Vgl.: Fryer, R. (1996) 67 Vgl.: Fryer, R. (1996), S.5 68 Vgl.: Fryer, R. (1996), S.10
|
|