| Kapitel 4.4.3 Logische Datenmodellierung | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
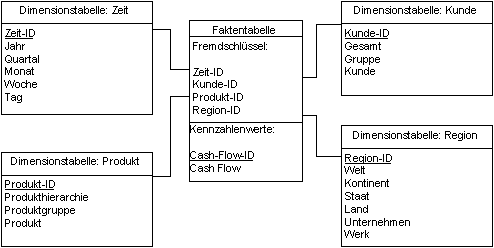
(Auszug aus der Diplomarbeit von Ralph Leipert: "Analytische Informationssysteme als Basis des Risikomanagement der Unternehmung") Im Prozeß der Datenmodellierung folgt nach der semantischen Datenmodellierung, die logische Datenmodellierung. Die logische Datenmodellierung ist im Gegensatz zur semantischen Datenmodellierung systemnah, d.h. der Modellierer weiß in dieser Phase, welche Art von DBS zur Anwendung kommt. Im Falle des Data Warehouse hat der Modellierer die Auswahl zwischen multidimensionaler und relationaler Datenbank. Für die Verwendung von objektorientierten Datenbanken ist ein objektorientiertes Datenmodell Voraussetzung. Dieses wird in der vorliegenden Arbeit nicht vorgestellt, jedoch sei in diesem Zusammenhang auf das Kapitel „Objektorientierter Ansatz“ und die einschlägige Literatur verwiesen.114 Im folgenden werden das Star-Schema und die Varianten dieses Schemas in Anlehnung an Hahne115 und Raden116 beschrieben. 4.4.3.1 Star-SchemaDas Star-Schema unterstützt die logische Datenmodellierung. Dabei werden die eigentlichen Werte der Kennzahlen in den Faktentabellen gespeichert und die Dimensionseinträge in sogenannten Dimensionstabellen. Außerdem sind die Beziehungen zu den entsprechenden Dimensionstabellen in den Faktentabellen hinterlegt.
Abbildung 4-21 Star-Schema Cash Flow Wie in obigem Schema zu sehen ist, werden Dimensionstabellen sternförmig um die Faktentabelle aufgebaut. Dabei wird bewußt von der logischen Datenmodellierung in operativen DBS abgewichen und die Daten nur noch in der zweiten Normalform modelliert anstatt in der dritten Normalform. Dadurch wird die logische Datenmodellierung flexibler. Die Modellierung der Daten in einem Star-Schema mit atomaren Daten auf der untersten Hierarchieebene innerhalb der Dimensionen ist unproblematisch.117 Werden jedoch aggregierte Daten modelliert, so gibt es zwei Möglichkeiten der Realisierung. Entweder man berechnet die aggregierten Daten in den Analyseabfragen oder die aggregierten Daten werden im Data Warehouse gespeichert. Hierbei ist zwischen Performanceverlusten und Administrationsaufwand abzuwägen. Im folgenden soll der zweite Fall näher erläutert werden. Werden aggregierte Daten im Data Warehouse gespeichert, ergibt sich das Problem der Unterscheidung von aggregierten und atomaren Daten. Dieses Problem kann durch Hinzufügen eines weiteren Attributs in die Dimensionstabellen gelöst werden. Dieses Attribut „level“ enthält Informationen über die Stufen bzw. Art der Aggregation.
Ein Problem bei der Einführung des Attributs „level“ liegt in der Inflexibiliät bei Veränderungen der Dimensionstabellen. Dadurch verändert sich nicht nur die Datenbasis des Data Warehouse, sondern es müssen auch Veränderungen in den Analysetools vorgenommen werden. 4.4.3.2 GalaxieEine Erweiterung des Star-Schemas ist die Galaxie. Diesen Begriff hat McGuff118 geprägt. Bei der Galaxie existiert nicht nur eine Faktentabelle sondern mehrere Faktentabellen. Die einzelnen Fakten (z.B. Kennzahlen: Umsatz, Cash Flow) werden jeweils in eigenen Faktentabellen gespeichert. Die verschieden Dimensionstabellen bleiben von den Veränderungen unberührt. Einzige Veränderung zum Star-Schema ist die Möglichkeit mehrerer Joins von Dimensionstabellen zu Faktentabellen. 4.4.3.3 Fact Constellation SchemaDas Fact Constellation Schema (FCS) ist eine Abwandlung des Star-Schemas. Der Kritik der Inflexibilität des Star-Schemas wurde durch das FCS entgegengewirkt. Im FCS werden die aggregierten Daten nicht mehr in den Dimensionstabellen modelliert, sondern es wird für jede denkbare Aggregationsform eine eigene Faktentabelle aufgebaut. Dadurch steigt die Anzahl der Faktentabellen entsprechend der Anzahl der Dimensionen explosionsartig an. Jedoch wird dadurch die Modellierung des Attributes „level“ überflüssig, so daß Veränderungen am Modell keine so weitreichenden Folgen der Modellveränderungen mit sich bringen würden wie beim Star-Schema. Die Modellierung eines FCS ist der Modellierung eines Star-Schemas dann vorzuziehen, wenn besonders große Faktentabellen entstehen.119 4.4.3.4 Partitionierte DimensionstabellenDie Probleme, die bei der Modellierung mit Hilfe des Attributes „level“ im Star-Schema entstehen, können auch durch Teilung der Dimensionstabellen gelöst werden. Dabei werden die Dimensionstabellen normalisiert120, das heißt die Dimensionstabellen werden entsprechend ihrer Aggregationsstufe („level“) aufgesplittet. Die Ersparnis durch das Weglassen des „level“-Eintrages und des geringeren Speicherplatzes muß mit einem Performance-Verlust erkauft werden.121
Abbildung 4-23 partitionierte Dimensionstabelle 4.4.3.5 Snow Flake SchemaDas Snow Flake Schema (SFS) ist eine Mischung aus partitionierten Dimensionstabellen und dem Fact Constellation Schema. Die Dimensionstabellen werden partitioniert und die Faktentabellen werden für jede Aggregations-Kombination jeweils als eine Faktentabelle gespeichert. Der Nachteil dieses SFS liegt in der Komplexität des Modelles. Mittels Tools kann diese Problematik durch Verwaltung des Data Warehouse auf semantischer Ebene umgangen werden.122 4.4.4 Objektorientierter AnsatzHeuer123 unterscheidet bei OODBS zwei unterschiedliche Entwicklungsrichtungen. Einmal gibt es OODBS deren Datenmodell auf eine objektorientierte Programmiersprache aufsetzt und durch Speicherstrukturen für Objekte und ein Persistenzkonzept ergänzt wird. Neuentwicklungen basieren jedoch auf einem neu entwickelten objektorientierten Datenbankmodell, bieten aber Schnittstellen der systeminternen Datenbanksprache zu den bekannten objektorientierten Programmiersprachen. In der Literatur werden immer beide Entwicklungsrichtungen in den Begriff der OODBS einbezogen. Das Objektorientierte Datenmodell ist aus statischer Sichtweise mit dem Semantischen Datenmodell (SDM) des Relationalen Datenmodells vergleichbar. Allerdings erreichen die SDM nur am Rande das Konzept der Objektidentität, welches im Vordergrund des Objektorientierten Datenmodell steht.124 Objektorientierte Datenmodelle unterstützen komplexe Typkonstruktoren und können somit komplexe Sachverhalte besser darstellen. Damit „echte“ Objektorientierung in AIS eingebracht wird, muß noch sehr viel getan werden, denn derzeit wird nur über die Metaebene und konzeptionelle Modellierungen der Bezug zu den relationalen DBS gesucht, aber die objektorientierte Modellierung nicht thematisiert.125 114 Heuer, A. (1992) 115 Vgl.: Hahne, M. (1998), S. 109ff 116 Vgl.: Raden, N. 117 Vgl.: Hahne, M. (1998), S. 111 118 Vgl.: Hahne, M. (1998), S.116; McGuff, F. (1996) 119 Vgl.: Hahne, M. (1998), S.117 120 Vgl.: Hahne, M. (1998), S.118 121 Vgl.: Hahne, M. (1998), S.120 122 Vgl.: Hahne, M. (1998), S.120-121 123 Vgl.: Heuer, A. (1998) 124 Vgl.: Heuer, A. (1992), S.339 125 Vgl.: Chamoni, P. (1998b), S.248 |
|