(Auszug aus der Diplomarbeit von Ralph Leipert: "Analytische Informationssysteme als Basis des Risikomanagement der Unternehmung")
3.1.3 Verteilte Datenbanksysteme
In den vorangegangenen Abschnitten wurde näher auf transaktionsorientierte DBS eingegangen und spezifische Eigenschaften hervorgehoben. Die Anforderungen müssen jedoch in einem großen Unternehmen nicht nur diesen einzelnen DBS entsprechen, sondern einem ganzen System, da in einem Unternehmen eine große Anzahl zumeist heterogener DBS existieren. Durch die Migration von historisch gewachsenen Datenbanken entstanden in den Unternehmen dezentrale DBS bzw. „Verteilte Datenbanksysteme i.w.S. (VDBS)“. Da die DBS meist unter unterschiedlichen Bedingungen bzw. Einsatzzwecken entstanden, existiert eine große Heterogenität in den Informationssystemen. Zur Überwindung dieser Heterogenität bzw. bei der Schaffung einer homogenen Datenbanklandschaft durch Integration, bilden die Unternehmen aus den verschiedenartigen DBS heterogene VDBS. VDBS, die nicht durch Integration vieler schon vorhandener DBS entstehen, sind meist homogener Natur. Diese DBS nennt man auch „Verteilte Datenbanksystem i.e.S.“. Eine genauere Klassifikation von VDBS ist in folgender Abbildung zu sehen und soll hier nicht weiter ausgeführt werden. Für diese VDBS hat Dates 12 Anforderungen definiert.
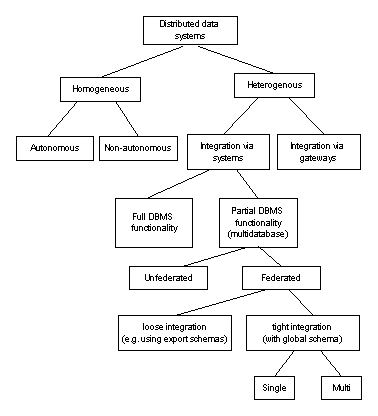
Abbildung 3-4 Taxonomy of distributed data systems
12 Anforderungen an VDBS von Dates
-
Lokale Autonomie
Lokale Autonomie bedeutet, daß jeder einzelne Rechner unabhängig von anderen Rechnern funktioniert. Hierbei sollen die Daten lokal verwaltet und bearbeitet werden. Die lokale Autonomie kann jedoch nicht 100%-ig erreicht werden. Ein Beispiel dafür ist die verteilte Serialisierbarkeit (Concurrency Control). Das Ziel bei VDBS ist jedoch, einen möglichst hohen Grad an lokaler Autonomie zu erreichen.
-
Unabhängigkeit von einem zentralen Rechner
Das VDBS sollte unabhängig von einem zentralen Rechner sein, da durch einen Systemabsturz des zentralen Rechners das ganze System ausfallen würde. Dadurch wäre die ständige Verfügbarkeit der Daten nicht gewährleistet. Durch einen zentralen Rechner könnte aber auch ein Engpaß entstehen, wenn viele Zugriffe zur gleichen Zeit erfolgen.
-
Dauerbetrieb
Ein VDBS sollte im Zustand eines Dauerbetriebes sein. Das heißt, daß jederzeit ein beteiligter Rechner angeschaltet werden kann und dieser sofort funktionsfähig in diesem DBS ist.
-
Ortstransparenz
Bei VDBS braucht der Anwender nicht zu wissen, wo die Daten gespeichert sind. Der Anwender sollte keinen Unterschied zwischen einer lokalen und einer verteilten DB sehen. Der Anwender bekommt das Ergebnis seiner Anfragen komplett zur gleichen Zeit präsentiert, damit für ihn die Verteilung der Daten nicht ersichtlich ist.
-
Fragmentierungstransparenz
Die Fragmentierungstransparenz ist ähnlich wie die Ortstransparenz. Da die Daten meist dort gespeichert werden, wo auf die Daten am häufigsten zugriffen wird, man jedoch nicht immer auf die ganzen Datensätze zugreifen muß, werden die Daten fragmentiert. Das heißt, daß die Daten entweder horizontal oder/und vertikal in Fragmente geteilt werden. Dies stellt keine Probleme dar, da den Verteilten Datenbankmodellen das relationale Datenbankmodell unterstellt wird. Hierbei sollte der Anwender nicht erfahren, daß und wie die Daten fragmentiert sind. Ortstransparenz und Fragmentierungstransparenz treten meist kombiniert auf, da die fragmentierten Daten auf unterschiedlichen Rechnern gespeichert sein können.
-
Replikationstransparenz
Um bestimmte Daten schnell zur Verfügung zu bekommen, können Kopien von Daten von entfernten Rechnern auf dem eigenen lokalen Rechner erstellt werden. Dies hat den Vorteil, das der zeitaufwendige Transport und die damit verbundenen hohen Datentransportkosten gespart werden. Ein weiterer Vorteil liegt in der schnellen Verfügbarkeit der Daten auf dem lokalen Rechner. Der Nachteil liegt auch sofort nahe; bei Änderung der Orginaldaten müssen auch alle Kopien geändert werden. Der Anwender soll jedoch nicht sehen, daß die Daten von einer Kopie stammen.
-
Verteilte Zugriffsprozesse (Query Processing)
Bei verteilten Zugriffsprozessen gibt es zwei Punkte zu beachten.
1. Wenn man z.B. in einem Büro in Augsburg bestimmte Datensätze abrufen möchte und diese in einer entfernten Stadt, wie z.B. Paris gespeichert sind, sendet man beim relationalen Datenbankmodell zwei Nachrichten. Einmal wird die Nachricht gesendet, daß die Datensätze benötigt werden, und zweitens werden die benötigten Datensätze gesendet. Bei nicht relationalen Datenbanken müssen 2n Nachrichten gesendet werden. Hierbei wird erst nach dem Datensatz gefragt, wird die Bedingung erfüllt wird der Datensatz gesendet, sowie gleich nach einem nächsten Datensatz nachgefragt, solange bis alle Datensätze gesendet wurden.
2. Das zweite Problem kommt hauptsächlich in VDBS i.e.S. vor. Muß eine Operation durchgeführt werden, bei der die jeweiligen Daten auf verschiedenen Rechnern gespeichert sind, stellt sich die Frage auf welchem Rechner die Operation durchgeführt werden soll. Erstens können die Daten von Rechner Y auf Rechner X oder umgekehrt gebracht werden. Es kann aber auch günstiger sein die Daten von Rechner X und von Rechner Y auf den Rechner Z zu bringen um die Operationen dort ausführen.
-
Verteiltes Transaktionsmanagment
Das verteilte Transaktionsmanagment beinhaltet zwei wichtige Kontrollmechanismen, „recovery control“ und „concurrency control“. Da in VDBS auch die Transaktionen verteilt sind, müssen die Kontrollmechanismen für einen gleichzeitigen Zugriff auf einen Datensatz, sowie für das Erkennen und Behandeln von inkonsistenten Zuständen umfangreicher sein als bei nichtverteilten DBS.
-
Hardwareunabhängigkeit
VDBS sollten unabhängig von der vorhandenen Hardware (z.B. APPLE-Rechner, IBM-Rechner und Großrechner) einsetzbar sein. Je mehr unterschiedliche Hardware ein DBS unterstützt bzw. integrieren kann, desto hardwareunabhängiger ist dieses System.
-
Betriebssystemsunabhängigkeit
Wie bei den Hardwareproblemen gibt es auch die Probleme mit dem Betriebssystem. Da man z.B. Rechner mit UNIX, MVS und PC/DOS Betriebssystemen hat, ist es schwierig, diese miteinander zu verknüpfen und Software laufen zu lassen. Deshalb sollte das DBS verschiedene Betriebssysteme unterstützen, um so unabhängig zu sein.
-
Netzwerkunabhängigkeit
Das DBS sollte möglichst auf vielen Netzwerksystemen laufen, da es wie bei den zwei vorangegangenen Punkten verschiedene Netzwerksysteme für verschiedene Hardware und Betriebssysteme gibt.
-
DBMS-Unabhängigkeit
Das DBS sollte bis zu einem bestimmten Grad Heterogenität unterstützen, d.h. daß in einem VDBS verschiedene DBMS laufen können.
3.1.4 Zusammenfassung
Transaktionsorientierte DBS eignen sich zur Speicherung und Verwaltung von großen Datenmengen. Aus dieser Funktion heraus entstanden auch die Anforderungen an VDBS. VDBS sind eine wichtige Anforderung an Managementunterstützungssysteme (MSS), da hierbei auf eine Vielzahl an Informationen in oft unterschiedlichen DBS zugegriffen werden muß. In diesen Anforderungen liegen jedoch auch die Problembereiche der Systeme. In der Vergangenheit hat man sich viel mit diesen Problembereichen auseinandergesetzt und MSS auf der Basis von OLTP entwickelt. Im folgenden Kapitel wird kurz auf die MSS eingegangen, um einen Überblick über die Stärken und Schwächen schon realisierter Systeme zu bekommen.
33 Vgl.: Date, C. J., (1995), S. 596ff
34 Vgl.: Bell/Grimson, (1994), S. 45 |
|
