| Kapitel 4.3 Data Mining | |
(Auszug aus der Diplomarbeit von Ralph Leipert: "Analytische Informationssysteme als Basis des Risikomanagement der Unternehmung") „Trotz der rasanten Fortschritte in der Computertechnologie sind die Möglichkeiten, Daten zu analysieren, weit hinter denen zurückgeblieben, sie zu generieren und zu speichern.“69 Mit der Entwicklung der Informationstechnologien in den letzten Jahren sind auch die Datenmengen gestiegen. So verdoppelt sich die gespeicherte Informationsmenge alle 20 Monate.70 In diesen Datenmengen stecken Zusammenhänge von Daten, die nur schwer aufzuspüren sind. Sei es, daß die Datenpools einen zu großen Umfang haben, oder die Daten für Analysezwecke zu unstrukturiert gespeichert sind. Durch Data Mining soll die Entwicklung der Datenanalyse wieder vorangetrieben werden. Einige Unternehmen nutzen schon auf dem Markt vorhandene Data Mining Systeme, so z.B. Kreditinstitute, um die Kreditwürdigkeit ihrer Kunden zu überprüfen. Aber auch im Marketing-Bereich oder in der Verbrechensbekämpfung71 werden Data Mining Tools eingesetzt. Allerdings sollte man unter Data Mining nicht das Allheilmittel für alle ungelösten Zusammenhänge sehen.72 Data Mining ist, wie Datawarehousing, ein kontinuierlicher und iterativer Prozeß und folgt keinesfalls einer magischen Formel.73 Mindestens die Hälfte der sogenannten Fortune-1000-Unternehmen werden nach einer Studie der Gartner Group bis zum Jahre 2000 Data Mining-Technologien nutzen.74 In den folgenden Kapiteln soll deshalb auf das Data Mining näher eingegangen werden. 4.3.1 Definition, Konzept, Anwendungsbereiche des Data Mining„Data Mining kann als Kernaktivität des umfangreichen Prozesses KDD (Knowledge Discovery in Databases) aufgefaßt werden.“75 Dieser Prozeß hat die Aufgabe, in umfangreichen Datenbeständen implizit vorhandenes Wissen zu finden und explizit zu machen.76 Der Begriff des Data Mining umschließt eine Menge von Technologien, mit deren Hilfe Unternehmen entscheidungsrelevante Informationen aus Datenbanken filtern und analysieren können.77 Data Mining hat die Aufgabe, Datenmuster zu erkennen und sie dem Anwender als interessantes Wissen zu präsentieren.78 Unter einem Datenmuster versteht man die Zusammenhänge zwischen Datensätzen, zwischen einzelnen Feldern der Datensätze, den Daten innerhalb eines Datensatzes sowie bestimmte Regelmäßigkeiten.79 Durch das Konzept des Data Warehouse können die Daten strukturiert und themenorientiert gespeichert werden. Dies ermöglichte auch die schnelle Entwicklung des Data Mining, da hierdurch nicht mehr Probleme der Vollständigkeit und der Konsistenz der Daten gelöst werden müssen. Die Datenmenge ist jedoch noch größer geworden, da im Data Warehouse auch Vergangenheitsdaten und aggregierte Daten gespeichert werden. Aus diesem Grund ist es mit herkömmlichen Tools nicht möglich, in dieser Datenbasis verborgene Zusammenhänge zu finden. 4.3.2 Ansätze des Data MiningEntsprechend der Zielsetzung des Data Mining, Zusammenhänge in der Datenbasis zu analysieren, gibt es verschiedene Ansätze zur Realisierung der Ziele. Dabei unterscheidet man die Klassifikation, die Clusterung und das Entdecken von Abhängigkeiten.80 Bei der Klassifikation werden Daten entsprechend ihren Attributsausprägungen zu bestimmten vordefinierten Klassen zugeordnet. Die Clusterung basiert auf einer Ähnlichkeitsanalyse, wobei Daten mit großer Ähnlichkeit jeweils zu Klassen vereint werden. Das Entdecken von Abhängigkeiten geschieht durch analysieren von gemeinsam auftretenden Attributkombinationen, deren durchschnittliche Häufigkeit des gemeinsamen Auftretens auffällig ist.81 Woods82 nennt folgende vier Bereiche, in denen derzeit Data Mining eingesetzt wird: Marktsegmentierung, Zielgruppenmarketing, Verbesserung der Kundenbindung, Prüfung der Kreditwürdigkeit. Marktsegmentierung Bei der Marktsegmentierung wird das Verhalten der Kunden, ähnlich einer Warenkorbanalyse, untersucht, und entsprechend des Ergebnisses das Produktangebot und die Ladeneinrichtung angepaßt.83 Zielgruppenmarketing Durch entsprechende Auswertungen von Kundendaten können Zielgruppen für bestimmte Produkte erkannt werden. Dadurch wird es möglich, potentielle Kunden gezielter zu erreichen. Verbesserung der Kundenbindung Ein großes Problem unserer Zeit ist die Kundenbindung.84 Nicht nur der Ausfall eines Kunden bedeutet für jedes Unternehmen Verlust, sondern auch die Anwerbung von neuen Kunden. Besonders stark bemerkbar ist zur Zeit der Kundenwechsel im Telekommunikations- und Internetmarkt. Durch die hohe Anzahl von Anbietern und den damit verbundenen billigen Konkurrenzprodukten wechseln viele Kunden ihre Anbieter. Dabei kann Data Mining helfen, potentielle Wechsler durch Zielgruppenmarketing zu identifizieren und geeignete Maßnahmen zu ergreifen, die zur Kundenbindung führen. Kreditwürdigkeitsprüfung Durch das Erkennen von bestimmten Zusammenhängen bei der Vergabe und der Rückzahlung von Krediten ist es möglich, Risiken bei Kreditvergaben zu bestimmen. Setzt ein Kreditinstitut solche Data Mining Tools ein, so kann es nicht nur einzelne risikoreiche Kredite besser handhaben, sondern auch bessere Zukunftsprognosen erstellen. Dadurch erreicht das Kreditinstitut z.B. Einsparungen bei der Unterlegung von Riskokapital zur Absicherung des Ausfallrisikos, wie auch Einsparungen durch bessere Absicherung von Krediten mit hoher Ausfallwahrscheinlichkeit. Damit diese Zusammenhänge gefunden werden können, müssen auf die Datenbasis Verfahren angesetzt werden, die solche Zusammenhänge herausfiltern können. Diese Verfahren können unterschiedlicher Natur sein und sollen im folgenden näher vorgestellt werden. 4.3.3 Verfahren des Data MiningZur Durchführung des Data Mining Prozesses können verschiedene Methoden und Verfahren genutzt werden. Im folgenden sollen ein paar wenige Verfahren kurz vorgestellt werden, die ihren Ursprung entweder in den statistisch-mathematischen Verfahren oder in der Künstlichen Intelligenz haben. Zum Data Mining eignen sich unter anderem Folgende Verfahren: Clusteranalyse, Künstliche Neuronale Netze, Kohonen Netze85, Entscheidungsbaumverfahren, Lineare Regression, Genetische Algorithmen, Chi-squared Automatic Interaction Detection (CHAID), Regelbasierte Systeme, grafisches Data Mining usw.. 86 4.3.3.1Clusteranalyse
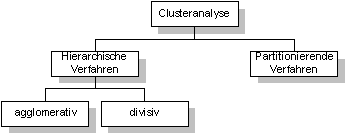
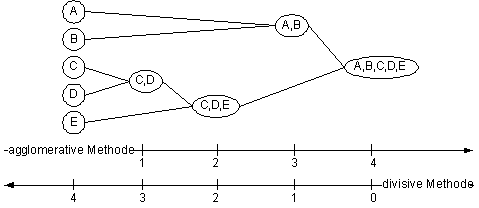
Abbildung 4-8 Clusteranalyse Die Clusteranalyse läßt sich in zwei verschiedene Methoden teilen. Dabei unterscheidet man die hierarchische Verfahren und die partitionierenden Verfahren.87 Die hierarchischen Verfahren kann man wiederum, je nach Vorgehensweise, in zwei Gruppen unterteilen. Aus den einzelnen Daten wird bei der agglomerativen Methode versucht, schrittweise Gruppen zu bilden. Dabei werden bei jedem Schritt jeweils zwei Gruppen zusammengefaßt. Die divisive Methode versucht im Gegensatz zur agglomerativen Methode die ganze Datenmenge in einzelne Gruppen zu teilen. Das Ziel beider Verfahren ist, die Datenmenge in k Klassen zu teilen.
Abbildung 4-9 hierarchische Methoden der Clusteranalyse Die Klassen (Cluster) werden auf der Basis der Verschiedenheit der Objekte gebildet. Dabei kommen Methoden wie euklidische Metrik oder City-Block-Metrik zum Einsatz. Diese Methoden bestimmen den Abstand von Objekten mit numerischen Merkmalen. Bei Objekten mit nominalen Merkmalen kann eine numerische Codierung vorgenommen werden, so daß wie bei Objekten mit numerischen Merkmalen verfahren werden kann. Es kann aber auch ein Unähnlichkeitsfaktor zur Abstandsmessung genutzt werden.88 Bei den partitionierenden Verfahren handelt es sich im Gegensatz zur hierarchischen Klassifikation um Optimierungsmethoden.89 Dabei wird nach unbekannten Datenmustern gesucht, indem die Daten in möglichst trennscharfe Klassen eingeteilt werden. Ein Vertreter dieser Methoden ist der K-Means-Algorithmus. Dieser versucht, die Daten in K-Cluster, durch Minimierung des euklidischen Abstandes von den Clusterzentren, zuzuordnen. Am Anfang wird jedem Cluster eine Dateneinheit zugeordnet und dann sukzessive die restlichen Daten entsprechend ihrem Abstand zu den Clusterzentren zugeordnet. Nach der Zuteilung wird durch bestimmte Austauschverfahren bzw. durch Verschieben der einzelnen Dateneinheiten geprüft, ob die Dateneinheiten optimal zu den Clustern zugeordnet wurden. Da dieses Verfahren nur ein Verbesserungsverfahren ist, kann nicht davon ausgegangen werden, daß ein Globaloptimum gefunden wird.90 4.3.3.2Künstliche Neuronale NetzeKünstliche Neuronale Netze (KNN) sind nichtlineare Prognoseverfahren, die der biologischen Informationsverarbeitung nachempfunden wurden und selbständig lernende Eigenschaften besitzen.91 Durch Verknüpfung von Neuronen mittels Output/Input-Beziehungen entstehen mathematische Modelle. Durch Strukturveränderungsverfahren ist es dem KNN möglich, Lerneffekte zu erreichen. Die eingesetzten Algorithmen werden als Lernregeln bezeichnet.
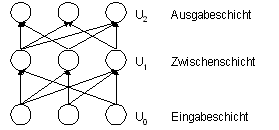
Abbildung 4-10 Multi Layer Perzeptron 1943 wurde durch McCulloch und Pitts das erste mathematische Neuronenmodell entwickelt. Rosenblatt entwickelte 1958 das erste Perzeptron. Das Perzeptron eignet sich zur Klassifikation von Eingaben, d.h. es ordnet eine Eingabe einer bestimmten Ausgabe zu. Das Perzeptron besteht aus zwei Schichten, einer Eingabe- und einer Ausgabeschicht. In dieser Hinsicht unterscheidet sich das Perzeptron nicht wesentlich von klassischen ökonomischen Modellen, die z.B. als lineare Regressionsmodelle eine Vielzahl von Eingabewerten linear zu einer Ausgabe kombinieren.92 Ein Multi Layer Perzeptron (MLP) besteht aus mehreren Schichten, der Eingabe-, der Zwischen- und der Ausgabeschicht. Die Zwischenschicht kann aus mehreren Neuronenschichten bestehen und wird auch als verborgene Schicht (Hidden-Layer) bezeichnet. Die Neuronen benachbarter Schichten sind miteinander verbunden und werden mit Gewichten bewertet.93 Bei der Klassifikation übernimmt immer die nachgelagerte Schicht die Klassifikation der Ausgaben der vorgelagerten Schicht. Die Verarbeitung der Informationen in der verborgenen Schicht ist für Außenstehenden nicht sichtbar.94 Durch die Ausgabeschicht kommen die verarbeiteten Informationen nach außen. Die Funktionsweise eines Perzeptron ist vergleichbar mit der eines Gehirns. Jedes Neuron besitzt einen Schwellwert. Wird dieser Schwellwert durch die Ausgaben der vorgelagerten Schicht (die Eingabe entspricht beim Perzeptron der Einfachheit halber der Summe der Ausgaben der vorgelagerten Neuronen) erreicht oder übertroffen, so gibt das Neuron ein anregendes Signal an die nachgelagerte Schicht ab. Wird der Schwellwert nicht erreicht, so wird ein hemmendes Signal abgegeben. Im folgenden Beispiel wird mit einem Perzeptron ein logisches „AND“ dargestellt. Wird von den Neuronen (x1,x2) ein anregendes Signal abgeschickt, so sind die Ausgabewerte jeweils 1. Zusammen ergibt sich somit ein Input in Höhe von 2, für das Neuron x3 mit dem Schwellwert von 2 (S=2). Damit ist der Schwellwert erreicht und das Neuron kann ein anregendes Signal senden. Sendet eines der beiden oder beide Neuronen (x1,x2) zusammen ein hemmendes Signal aus, so ist der Neuronen-Output von x1 oder x2 gleich Null und der Schwellwert kann nicht mehr erreicht werden. Das Neuron x3 sendet somit ein hemmendes Signal (Null) aus.
Abbildung 4-11 Perzeptron mit einem logischen „AND“ Mit Hilfe von Lernregeln kann dieses bisher statisch betrachtete Netz in der Struktur verändert werden. Dabei sind folgende Veränderungen des Netzes möglich.
Es werden zwei Lernverfahren bei KNN unterschieden. Einmal das überwachte Lernen und andererseits das unüberwachte Lernen. Beim überwachten Lernen werden dem Netz Eingabe- und Ausgabemuster vorgegeben. Dabei hat das Lernverfahren die Aufgabe, die Struktur des Netzes so zu ändern, daß am Ende bei der Eingabe der Eingabemuster die vorgegeben Ausgabemuster herauskommen. Beim unüberwachten Lernen werden nur die Eingabemuster in das Netz eingegeben. Das Lernverfahren hat hierbei die Aufgabe ähnliche Eingabemuster in bestimmte Klassen einzuordnen. In der Praxis werden für ökonomische Anwendungen meist überwachte Lernverfahren eingesetzt. Beispiele für diese Lernverfahren sind die Hebb-Regel, die Delta-Regel und der Back Propagation Algorithmus. Beim Back Propagation Algorithmus wird ausgehend von den Eingaben (Lerndaten) über die verborgene Schicht die Ausgabe eines KNN berechnet. Dieses Ergebnis wird mit dem gewünschten Ergebnis verglichen. Die Lerndaten dienen dem Netz zum Training. Mit Hilfe von Testdaten wird das Netz nach verschiedenen Trainingszyklen nach Fehlern überprüft und anhand der Ergebnisse die Lernregeln für das Netz festgelegt. Dabei wird versucht, den Ausgabefehler so klein wie möglich zu halten. Ausgehend von der Ausgabeschicht werden Korrekturen mittels der Lernregeln in Richtung der Eingabeschicht vorgenommen.95 Am Ende wird mit der Validierungsmenge die Güte des fertig entwickelten Netzes überprüft.96 Mit dieser Fähigkeit der Selbststrukturierung sind KNN in der Lage, eine optimale Korrespondenz (bzgl. einer Distanzfunktion wie z.B. dem mittleren quadratischen Fehler) zwischen Ein- und Ausgaben darzustellen.97 Ein großer Nachteil von KNN besteht darin, daß die KNN von einer derartigen Komplexität gekennzeichnet sind, daß ihre inneren Zusammenhänge nur schwerlich nachvollziehbar sind. Ein weiteres großes Problem bei den Lernverfahren ist das Overlearning, d.h. das Netz liefert zu den bestimmten Eingabemustern ein exaktes Ergebnis, so daß die Generalisierungsfähigkeit des Netzes verloren gehen kann. Das Netz neigt hierbei mehr zum „Merken“ der Trainingsdaten, als zur Abstraktion der darin enthaltenen Wirkungszusammenhänge, so besteht die Gefahr der zu großen Anpassung der KNN an spezielle Marktsituationen in der Vergangenheit98.
Abbildung 4-12 KNN zur Risikoprognose Im Risikomanagement können KNN z.B. zur Klassifikation von Unternehmen in bestimmte Risikokategorien eingesetzt werden. Es ist aber auch denkbar, anhand von Risiko- und Unternehmensdaten das zukünftige Risiko zu prognostizieren. Hierzu müssen aber große Datenmengen über das Unternehmen und die dazugehörigen Risiken existieren, damit ein dafür vorgesehenes KNN auch trainiert und getestet werden kann. Eine weitere Möglichkeit des Einsatzes für KNN im Risikomanagement könnte das Aufdecken von bisher unbekannten Zusammenhängen sein, z.B. Korrelationszusammenhänge. In der Praxis werden bisher KNN zur Bonitätsprüfung bei Kreditvergaben anstatt einer statistischen Bonitätsprüfung eingesetzt. Aber auch für Prognoseprobleme an Finanzmärkten zur Berechnung von Aktien- und Wechselkursen, sowie Zinsentwicklungen sind KNN einsetzbar. 4.3.4 Problembereiche des Data MiningDurch die Anwendung von Data Mining Tools kommen einige Probleme auf die Entwickler und Anwender zu. Da das Konzept des Data Mining in der ursprünglichen Fassung visionär ist, konnten aus heutiger Sicht die Anforderungen an die Datenmustererkennung nur zum Teil gelöst werden.99 Hierzu zählen Probleme wie Autonomie, Datenproblematik, Verständlichkeit, Sicherheit und Interessantheit. Zu den Problemen der Autonomie zählt vor allem die Begriffsabgrenzung. Bei der Diskussion dieses Problems sehen Hagedorn, Bissantz und Mertens100 zwei Richtungen. Einige Autoren verstehen unter Data Mining einen regelkreisähnlichen Prozeß, der mit einer Hypothese des Anwenders beginnt und abhängig von den Zwischenergebnissen bis zum befriedigendem Resultat verfeinert wird. Andere Autoren sehen in dem Prozeß keine vorher definierten Hypothesen der Anwender, sondern es sollte nach eher allgemein formulierten Auffälligkeiten gesucht werden, die dann durch das Data Mining System in Form von Regeln oder Aussagen präsentiert werden.101 Ein weiteres Problem wird in der Datenproblematik gesehen. Dies sind meist Probleme, die in der heterogen Umgebung der Informationssysteme liegen. Dabei treten Probleme wie Inkonsistenzen, Datenredundanzen, Unvollständigkeiten sowie Integrationsprobleme auf der konzeptionellen Ebene (Detaillierungs-, Bezeichnungskonflikte, usw.) auf. Des weiteren müssen die präsentierten Informationen in einer verständlichen Form mit einer angegebenen Sicherheit bzw. Wahrscheinlichkeit ausgegeben werden. Die gefunden Informationen müssen vor allem für den Benutzer relevant sein. Es sollen keine unnützen, bedeutungslosen, trivialen und schon bekannten Informationen generiert werden. Einige dieser Probleme wie die der Datenproblematik und der Interessantheit können durch eine gut aufbereitete Datenbasis minimiert werden. Hierzu trägt das Konzept des Data Warehouse bei, in dem Daten vor allem themenorientiert aufbereitet werden. Dadurch werden nur nützliche anwendungsorientierte Daten aus den operativen DBS herausselektiert, aufbereitet und verwaltet. Außerdem erreicht man durch das Konzept des Data Warehouse eine konsistente und voll integrierte Datenbasis, mit der einige Probleme des Data Mining gelöst werden. Ein wichtiger Punkt dabei ist jedoch eine vollständige Datenmodellierung, die den Anforderungen der AIS standhält. 4.3.5 ZusammenfassungWie in diesem Kapitel beschrieben, haben die Methoden bzw. Verfahren des Data Mining eine längere Vergangenheit als die AIS. Mit dem Konzept des Data Warehouse kommt diesen Methoden jedoch eine neue Bedeutung zu. Durch die Aufbereitung der operativen Daten zur Speicherung im Data Warehouse bekommen die Daten eine neue Qualität. Während frühere Systeme, wie z.B. die Wissensbasierten Systeme, die die Daten themenorientiert speichern, um sie dann durch Regeln zu Wissen zu generieren, speichert das Data Warehouse diese Daten auch noch aggregiert, konsolidiert und zeitbezogen ab. Ein weiterer Vorteil des Data Warehouse ist die Nutzung der Datenbasis auch für andere Anwendungen wie z.B. OLAP-Werkzeuge. Dem Data Mining kommt im Risikomanagement eine bedeutende Rolle zu. Während sich Versicherungen und Banken in der Vergangenheit mit den operativen DBS für ihre Analysen begnügen mußten, können sie heute mit Hilfe des Data Mining in den aufbereiteten Daten des Data Warehouse nach verborgenen Strukturzusammenhängen in den Datenbeständen suchen. Durch die Analyseeigenschaften der Daten im Data Warehouse eignen sich die Daten nicht nur für Analysen mit OLAP-Anwendungen sondern auch mit Data-Mining-Tools. Den Unternehmen ist es durch Aufdecken von verborgenen Zusammenhängen in Verbindung mit Risiken möglich, die Risiken besser zu quantifizieren und zu verwalten. Außerdem können bessere Zukunftsprognosen die Folge von zusätzlichen Wissens über Risikozusammenhänge bedeuten. Bei Versicherungen und Banken ist es zu dem möglich Unternehmen, Personen und Produkte besser bestimmten Risikoklassen zuzuordnen. Dadurch können Versicherungsschäden bzw. Kreditausfälle besser kalkuliert und abgesichert werden. 69 Woods, E. (1998), S.16 70 Vgl.: Dilly, Ruth in: http://www-pcc.qub.ac.uk/tec/courses/datamining/stu-notes/dm_book_2.html, S.1 71 Vgl.: Buser, U. (1995), S.30-31 72 Vgl.: Woods, E. (1998), S.17 73 Vgl.: Woods, E. (1998), S.17 74 Vgl.: Data Mining Forum in: www.data-mining.de/mining.htm 75 Chamoni, P. (1998a), S. 303 76 Vgl.: Düsing, Roland (1998), S. 292 77 Vgl.: Data Mining Forum in: www.data-mining.de/mining.htm 78 Vgl.: Hagedorn, J. / Bissantz, N / Mertens P (1997), S.601 79 Vgl.: Hagedorn, J. / Bissantz, N / Mertens P (1997), S.601 80 Vgl.: Düsing, Roland (1998), S. 297 81 Vgl.: Düsing, Roland (1998), S. 297 82 Vgl.: Woods, E. (1998), S.17 83 Vgl.: Woods, E. (1998), S.17 84 Vgl.: Woods, E. (1998), S.17 85 Vgl.: Volmer, R. / Lehrbaß, F. B. (1997) S.339-343 86 Vgl.: Hagedorn J. / Bissantz N. / Mertens P. (1997) S. 604ff; Chamoni, P. (1998a); Bissantz, N. (1998); Deventer, R. / van HOOF, A. (1998); Dilly, Ruth: Kapitel 3.1-3.3 87 Vgl.: Chamoni, P. (1998a), S.306 88 Vgl.: Chamoni, P.: (1998a), S.307 89 Vgl.: Chamoni, P.: (1998a), S.308 90 Vgl.: Chamoni, P.: (1998a), S.308 91 Vgl.: Data Mining Forum in: www.data-mining.de/mining.htm 92 Vgl.: Heitkamp, D. F. H. (1996), S.285 93 Vgl.: Chamoni, P. (1998a), S.314 94 Vgl.: Baetge, J. / Kruse, A. / Uthoff, C. (1996), S.275 95 Vgl.: Baetge, J. / Kruse, A. / Uthoff, C. (1996), S. 275 96 Vgl.: Baetge, J. / Kruse, A. / Uthoff, C. (1996), S. 276 97 Vgl.: Heitkamp, D. F. H. (1996), S. 285; Hornik, K. / Stinchcombe, M. / White, H.: (1989), S. 259-366 98 Vgl.: Heitkamp, D. F. H. (1996), S. 285 99 Vgl.: Hagedorn J. / Bissantz N. / Mertens P. (1997), S. 602 100 Vgl.: Hagedorn J. / Bissantz N. / Mertens P. (1997), S. 602 101 Vgl.: Hagedorn J. / Bissantz N. / Mertens P. (1997), S. 602; Gebhardt, F. (1994), S. 9-15
|
|